Tool Deep Dive: PRINCE
Tool Name: PRINCE (PRobability INfinite Chained Elements)
Version Reviewed: 0.12
Author: Jens Steube, (Atom from Hashcat)
OS Supported: Linux, Mac, and Windows
Password Crackers Supported: It is a command line tool so it will work with any cracker that accepts input from stdin
1/4/2015: Removed a part in the Algorithm Design section that talked about a bug that has since been fixed in version 0.13
1/4/2015: Added an additional test with PRINCE and JtR Incremental after a dictionary attack
1/4/2015: Added a section for using PRINCE with oclHashcat
As stated in the description, PRINCE combines words from the input dictionary to produce password guesses. The first step is processing the input dictionary. Feeding it an input dictionary of:
Finding #1: Make sure you remove duplicate words from your input dictionary *before* you run PRINCE
After PRINCE reads in the input dictionary it stores each word, (element), in a table consisting of all the words of the same length. PRINCE then constructs chains consisting of 1 to N different elements. Right now it appears that N is equal to eight, (confirmed when using the --elem-cnt-min option). It does this by setting up structures of the different tables and then filling them out. For example with the input dictionary:
Prince:
run laki$ ../../../Tools/princeprocessor-0.12/pp64.app < ../../../dictionaries/passwords_top10k.txt | ./john --format=raw-sha1-linkedin -stdin one_hash.txt
Loaded 1 password hash (Raw SHA-1 LinkedIn [128/128 SSE2 intrinsics 8x])
guesses: 0 time: 0:00:02:00 c/s: 1895K trying: asdperkins6666 - bobperkins

What I wanted to point out was that for a fast hash, (such as unsalted SHA1 in this case), since PRINCE is not integrated into OCLHashcat it can't push guesses fast enough to the GPU to take full advantage of the GPU's cracking potential. In this case, the GPU is only at around 50% utilization. That is a longer way of saying that while you still totally make use of OCLHashcat when using PRINCE, it may be adventurous to also run dictionary based rules on the guesses PRINCE generates. Since those dictionary rules are applied on the GPU itself you can make a lot more guesses per second to take full advantage of your cracking hardware. This is also something Atom recommends and he helpfully included two different rulesets with the PRINCE tool itself.
Side note: PRINCE plows though the LinkedIn list pretty effectively. To get the screenshot above I had to run the cracking session twice since otherwise the screen would have been filled with cracked passwords.
Click on the graph for a zoomed in picture. As you can see, Prince did really well starting out but then quickly became less effective. This is because it used most, (if not all), of the most common words in the RockYou list first so it acted like a normal dictionary attack. At the same time, Incremental Mode was starting to catch up by the end of the run. While I could continue to run this test over a longer cracking session, this actually brings up the next two experiments....
Experiment 2) PRINCE and Dictionary Attacks targeting the MySpace list
Experiment Setup:
This is the same as the previous test targeting the MySpace dataset, but this time using dictionary attacks. For JtR, I stuck with the default ruleset and the more advanced "Single" ruleset. I also ran a test using Hashcat and the ruleset Atom included along with PRINCE, (prince_generated.rule). For all the dictionary attacks, I used the RockYou top 100k dictionary to keep them comparable to the PRINCE attack.
Cracking Length: I gave each session up to 1 billion guesses, but the two JtR attacks were so short that I only displayed the first 100 million guesses on the graph so they wouldn't blend in with the Y-axis. The hashcat attack used a little over 700 million guesses which I annotated its final results on the graph. Side note, (and this merits another blog post), but Hashcat performs its cracking sessions using word order, vs JtR's rule order. I suspect this is to make hashcat faster when cracking passwords using GPUs. You can read about the difference in those two modes in one of my very first blog posts back in the day. What this means is that Hashcat's cracking sessions tend to be much less front loaded unless you take the time to run multiple cracking sessions using smaller mangling rulesets.
Commands used:
laki$ ../../../Tools/princeprocessor-0.12/pp64.app < ../../../dictionaries/Rockyou_top_100k.txt | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../John/john-1.7.9-jumbo-7/run/john -wordlist=../../../dictionaries/Rockyou_top_100k.txt -rules=wordlist -stdout | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../John/john-1.7.9-jumbo-7/run/john -wordlist=../../../dictionaries/Rockyou_top_100k.txt -rules=single -stdout | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000

Commands used:
laki$ ../../../John/john-1.8.0-jumbo-1/run/john -wordlist= ../../../dictionaries/Rockyou_full_ordered.txt -rules=single -stdout | python checkpass2.py -t ../../../Passwords/myspace.txt -u uncracked_myspace.txt
laki$ ../../../Tools/princeprocessor-0.13/pp64.app < ../../../dictionaries/Rockyou_full_ordered.txt | python checkpass2.py -t ../../../Passwords/uncracked_myspace.txt -m 10000000000 -c 23865
laki$ ../../../Tools/princeprocessor-0.13/pp64.app < ../../../dictionaries/Rockyou_top_100k.txt | python checkpass2.py -t ../../../Passwords/uncracked_myspace.txt -m 10000000000 -c 23865
laki$ ../../../John/john-1.8.0-jumbo-1/run/john -incremental=UTF8 -stdout | python checkpass2.py -t ../../../Passwords/uncracked_myspace.txt -m 10000000000 -c 23865
Experiment Results:

I'll guiltily admit before running this test I hadn't been that impressed with PRICE. That's because I had been running it with the top 100k RockYou dictionary. As you can see, with the smaller dictionary it performed horribly. When I ran the new test with the full RockYou dictionary though, PRINCE did significantly better than an Incremental brute force attack. Yes, cracking 1.5% more of the total set might not seem like much, but it will take Incremental mode a *long* time to catch up to that. Long story short though, PRINCE's effectiveness is extremly dependend on the input dictionary you use for it.
Like most surprising test results, this opens up more questions then it solves. For example, what exactly is going on with PRINCE to make it so much more effective with the new dictionary. My current hypothesis is that it is emulating a longer dictionary attack, but I need to run some more tests to figure out if that's the case or not. Regardless, these results show that PRINCE appears to be a very useful tool to have in your toolbox if you use the right input dictionary for it.
Other References:
Version Reviewed: 0.12
Author: Jens Steube, (Atom from Hashcat)
OS Supported: Linux, Mac, and Windows
Password Crackers Supported: It is a command line tool so it will work with any cracker that accepts input from stdin
Blog Change History:
1/4/2015: Fixed some terminology after talking to Atom1/4/2015: Removed a part in the Algorithm Design section that talked about a bug that has since been fixed in version 0.13
1/4/2015: Added an additional test with PRINCE and JtR Incremental after a dictionary attack
1/4/2015: Added a section for using PRINCE with oclHashcat
Brief Description:
PRINCE is a password guess generator and can be thought of as an advanced Combinator attack. Rather than taking as input two different dictionaries and then outputting all the possible two word combinations though, PRINCE only has one input dictionary and builds "chains" of combined words. These chains can have 1 to N words from the input dictionary concatenated together. So for example if it is outputting guesses of length four, it could generate them using combinations from the input dictionary such as:4 letter word
2 letter word + 2 letter word
1 letter word + 3 letter word
1 letter word + 1 letter word + 2 letter word
1 letter word + 2 letter word + 1 letter word
1 letter word + 1 letter word + 1 letter word + 1 letter word
..... (You get the idea)
Algorithm Design:
As of this time the source-code of PRINCE has not been released. Therefore this description is based solely on At0m's Passwords14 presentation, talking to At0m himself on IRC as well as running experiments with various small dictionaries using the tool itself and manually looking at the output.As stated in the description, PRINCE combines words from the input dictionary to produce password guesses. The first step is processing the input dictionary. Feeding it an input dictionary of:
aresulted it in generating the following guesses:
a
aTherefore, it's pretty obvious that the tool does not perform duplicate detection when loading a file
a
aa
aa
aaa
aaa
aaaa
aaaa
...(output cut to save space)
Finding #1: Make sure you remove duplicate words from your input dictionary *before* you run PRINCE
After PRINCE reads in the input dictionary it stores each word, (element), in a table consisting of all the words of the same length. PRINCE then constructs chains consisting of 1 to N different elements. Right now it appears that N is equal to eight, (confirmed when using the --elem-cnt-min option). It does this by setting up structures of the different tables and then filling them out. For example with the input dictionary:
aIt will generate the guesses:
a
aa
aaa
aaaa
aaaaa
aaaaaa
aaaaaaa
aaaaaaaa
This isn't to say that it won't generate longer guesses since elements can be longer then length 1. For example with the following input dictionary:
a
bb
BigInput
It generates the following guesses
a
aa
bba
aabb
bbabb
bbbbbb
abbbbbb
BigInput
BigInputbb
bbBigInputbb
bb
aaa
...(output cut to save space)
Next up, according to the 35 slide of the Passwords14 talk it appears that Prince should be sorting these chains according to keyspace. This way it can output guesses from the chains with the smallest keyspace first. This can be useful so it will do things like append values on the end of dictionary words before it tries a full exhaustive brute force of all eight character passwords. While this appears to happen to a certain extent, something else is going on as well. For example with the input dictionary:
a
b
cc
It would output the following results:
a
b
cc
cca
cccc
ccacc
cccccc
acccccc
cccccccc
cccccccccc
cccccccccccc
aa
ccb
acca
ccbcc
aacccc
bcccccc
aacccccc
.....(Lots of results omitted).....
aaaabbbb
baaabbbb
abaabbbb
bbaabbbb
aababbbb
bababbbb
abbabbbb
bbbabbbb
aaabbbbb
baabbbbb
This is a bit of a mixed bag. While it certainly saved the highest keyspace chains for the end, it didn't output everything in true increasing keyspace order since elements of length 1, (E1), had two items, while elements of length 2, (E2), only had one item, but it outputted E1 first. I have some suspicions that the order it outputs its chains is independent on how many items actually are in each element for that particular run, (aka as long as there is at least one item in each element, it is independent of your input dictionary). I don't have anything hard to back up that suspicion though beyond a couple of sample runs like the one above. Is this a problem? Quite honestly, I'm not really sure, but it is something to keep in mind. When I talked to Atom about this he said that password length compared to the average length of items in the training set also influenced the order at which chains were selected so that may have something to do with it.
Finding #2: PRINCE is not guaranteed to output all chains in increasing keyspace order, though it appears to at least make an attempt to do so
Additional Options:
--elem-cnt-max=NUM: This limits the number of elements that can be combined to NUM. Aka if you set NUM to 4, then it can combine up to 4 different elements. So if you had the input word 'a' it could generate 'aaaa' but not 'aaaaa'. This may be useful to limit some of the brute forcing it does.
The rest of the options are pretty self explanatory. One request I would have is for PRINCE to save its position automatically, or at least print out the current guess number when it is halted, to make it easier to restart a session by using the "--skip=NUM" option.
The rest of the options are pretty self explanatory. One request I would have is for PRINCE to save its position automatically, or at least print out the current guess number when it is halted, to make it easier to restart a session by using the "--skip=NUM" option.
Performance:
PRINCE was written by Atom so of course it is fast. If you are using a CPU cracker it shouldn't have a significant impact on your cracking session even if you are attacking a fast hash. For comparison sake, I ran it along with JtR's incremental mode on my MacBook Pro.Prince:
run laki$ ../../../Tools/princeprocessor-0.12/pp64.app < ../../../dictionaries/passwords_top10k.txt | ./john --format=raw-sha1-linkedin -stdin one_hash.txt
Loaded 1 password hash (Raw SHA-1 LinkedIn [128/128 SSE2 intrinsics 8x])
guesses: 0 time: 0:00:02:00 c/s: 1895K trying: asdperkins6666 - bobperkins
JtR Incremental Mode:
run laki$ ./john -incremental=All -stdout | ./john --format=raw-sha1-linkedin -stdin one_hash.txt
Loaded 1 password hash (Raw SHA-1 LinkedIn [128/128 SSE2 intrinsics 8x])
guesses: 0 time: 0:00:00:14 c/s: 2647K trying: rbigmmi - rbigm65
Using PRINCE with OCLHashcat:
Below is a sample screen shot of me using PRINCE as input for OCLHashcat on my cracking box, (it has a single HD7970 GPU). Ignore the --force option as I had just installed an updated video card driver and was too lazy to revert back to my old one that OCLHashcat supports. I was also too lazy to boot into Linux since I was using Excel for this post and my cracking box also is my main computer...What I wanted to point out was that for a fast hash, (such as unsalted SHA1 in this case), since PRINCE is not integrated into OCLHashcat it can't push guesses fast enough to the GPU to take full advantage of the GPU's cracking potential. In this case, the GPU is only at around 50% utilization. That is a longer way of saying that while you still totally make use of OCLHashcat when using PRINCE, it may be adventurous to also run dictionary based rules on the guesses PRINCE generates. Since those dictionary rules are applied on the GPU itself you can make a lot more guesses per second to take full advantage of your cracking hardware. This is also something Atom recommends and he helpfully included two different rulesets with the PRINCE tool itself.
Side note: PRINCE plows though the LinkedIn list pretty effectively. To get the screenshot above I had to run the cracking session twice since otherwise the screen would have been filled with cracked passwords.
Big Picture Analysis:
The main question of course is how does this tool fit into a cracking session? Atom talked about how he saw PRINCE as a way to automate password cracking. The closest analogy would be John the Ripper's default behavior where it will start with Single Crack Mode, (lots of rules applied to a very targeted wordlist), move on to Wordlist mode, (basic dictionary attack), and then try Incremental mode, (smart bruteforce). Likewise with PRINCE depending on how you structure your input dictionary it can act as a standard dictionary attack, (appending/prepending digits to input words for example), combinator attack, (duh), and pure brute force attack, (trying all eight character combos). It can even do a limited passpharse attack though it gets into "Correct Horse Battery Staple" keyspace issues then. For example, with the input dictionary of:CorrectIt will generate all four word combinations such as:
Horse
Battery
Staple
HorseHorseCorrectBattery
HorseHorseBatteryBattery
HorseCorrectCorrectHorse
HorseBatteryCorrectHorse
HorseCorrectBatteryHorse
HorseBatteryBatteryHorse
CorrectCorrectHorseHorse
BatteryCorrectHorseHorse
CorrectBatteryHorseHorse
BatteryBatteryHorseHorse
When talking about passpharse attacks then, keep in mind it doesn't have any advanced logic so you are really doing a full keyspace attack of all the possible combinations of words.
The big question then is how does it compare against other attack modes when cracking passwords? You know what this means? Experiments and graphs!
I decided I would base my first couple of comparisons using the demos Atom had listed in his slides as a starting point. I figure no-one would know how to use PRINCE better than he would. Note: these are super short runs. While I could explain that away by saying this simulates targeting a slow hash like bcrypt, the reality is Atom made some noticeable changes in PRINCE while I was writing this post, (yay slow update schedule). I figured it would be good to make some quick runs with the newer version to get a general idea of how PRINCE performs and then post a more realistic length run at a later time. Also, this way I can get feedback on my experiment design so I don't waste time running a longer cracking session on a flawed approach.
Experiment 1) PRINCE, Hashcat Markov mode, and JtR Incremental mode targeting the MySpace list
Experiment Setup:
The input dictionary for PRINCE was the top 100k most popular passwords from the RockYou list, as this is what Atom used. For Hashcat I generated a stats file on the full RockYou list and used a limit of 16. For JtR I ran the default Incremental mode using the "All" character set. The target list was the old MySpace list. The reason why I picked that vs the Stratfor dataset which Atom used was simply because there are a ton of computer generated passwords, (aka default passwords assigned to users), in the Startfor dataset so it can be a bit misleading when used to test against.
Cracking Length: 1 billion guesses
Commands used:
laki$ ../../../Tools/princeprocessor-0.12/pp64.app < ../../../dictionaries/Rockyou_top_100k.txt | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../John/john-1.7.9-jumbo-7/run/john -incremental=All -stdout | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../hashcat/statsprocessor-0.10/sp64.app --threshold=16 ../../../hashcat/statsprocessor-0.10/hashcat.hcstat | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
Experiment Results:
The big question then is how does it compare against other attack modes when cracking passwords? You know what this means? Experiments and graphs!
I decided I would base my first couple of comparisons using the demos Atom had listed in his slides as a starting point. I figure no-one would know how to use PRINCE better than he would. Note: these are super short runs. While I could explain that away by saying this simulates targeting a slow hash like bcrypt, the reality is Atom made some noticeable changes in PRINCE while I was writing this post, (yay slow update schedule). I figured it would be good to make some quick runs with the newer version to get a general idea of how PRINCE performs and then post a more realistic length run at a later time. Also, this way I can get feedback on my experiment design so I don't waste time running a longer cracking session on a flawed approach.
Experiment 1) PRINCE, Hashcat Markov mode, and JtR Incremental mode targeting the MySpace list
Experiment Setup:
The input dictionary for PRINCE was the top 100k most popular passwords from the RockYou list, as this is what Atom used. For Hashcat I generated a stats file on the full RockYou list and used a limit of 16. For JtR I ran the default Incremental mode using the "All" character set. The target list was the old MySpace list. The reason why I picked that vs the Stratfor dataset which Atom used was simply because there are a ton of computer generated passwords, (aka default passwords assigned to users), in the Startfor dataset so it can be a bit misleading when used to test against.
Cracking Length: 1 billion guesses
Commands used:
laki$ ../../../Tools/princeprocessor-0.12/pp64.app < ../../../dictionaries/Rockyou_top_100k.txt | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../John/john-1.7.9-jumbo-7/run/john -incremental=All -stdout | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../hashcat/statsprocessor-0.10/sp64.app --threshold=16 ../../../hashcat/statsprocessor-0.10/hashcat.hcstat | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
Experiment Results:
Click on the graph for a zoomed in picture. As you can see, Prince did really well starting out but then quickly became less effective. This is because it used most, (if not all), of the most common words in the RockYou list first so it acted like a normal dictionary attack. At the same time, Incremental Mode was starting to catch up by the end of the run. While I could continue to run this test over a longer cracking session, this actually brings up the next two experiments....
Experiment 2) PRINCE and Dictionary Attacks targeting the MySpace list
Experiment Setup:
This is the same as the previous test targeting the MySpace dataset, but this time using dictionary attacks. For JtR, I stuck with the default ruleset and the more advanced "Single" ruleset. I also ran a test using Hashcat and the ruleset Atom included along with PRINCE, (prince_generated.rule). For all the dictionary attacks, I used the RockYou top 100k dictionary to keep them comparable to the PRINCE attack.
Cracking Length: I gave each session up to 1 billion guesses, but the two JtR attacks were so short that I only displayed the first 100 million guesses on the graph so they wouldn't blend in with the Y-axis. The hashcat attack used a little over 700 million guesses which I annotated its final results on the graph. Side note, (and this merits another blog post), but Hashcat performs its cracking sessions using word order, vs JtR's rule order. I suspect this is to make hashcat faster when cracking passwords using GPUs. You can read about the difference in those two modes in one of my very first blog posts back in the day. What this means is that Hashcat's cracking sessions tend to be much less front loaded unless you take the time to run multiple cracking sessions using smaller mangling rulesets.
Commands used:
laki$ ../../../Tools/princeprocessor-0.12/pp64.app < ../../../dictionaries/Rockyou_top_100k.txt | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../John/john-1.7.9-jumbo-7/run/john -wordlist=../../../dictionaries/Rockyou_top_100k.txt -rules=wordlist -stdout | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../John/john-1.7.9-jumbo-7/run/john -wordlist=../../../dictionaries/Rockyou_top_100k.txt -rules=single -stdout | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
laki$ ../../../hashcat/hashcat-0.48/hashcat-cli64.app --stdout -a 0 -r ../../../Tools/princeprocessor-0.12/prince_generated.rule ../../../dictionaries/Rockyou_top_100k.txt | python checkpass2.py -t ../../../Passwords/myspace.txt -m 1000000000
Experiment Results:
As you can see, all of the dictionary attacks performed drastically better than the PRINCE over the length of their cracking sessions. That's to be expected since their rulesets were crafted by hand while PRINCE generates its rules automatically on the fly. I'd also like to point out that once the normal dictionary attacks are done, PRINCE keeps on running. That's another way of saying that PRINCE still has a role to play in a password cracking session even if standard dictionary attacks initially outperform it. All this test points out is if you are going to be running a shorter cracking session you would be much better off running a normal dictionary based attack instead of PRINCE. This does lead to my next question and test though. After you run a normal dictionary attack, how does PRINCE do in comparison to a Markov brute force based attack?
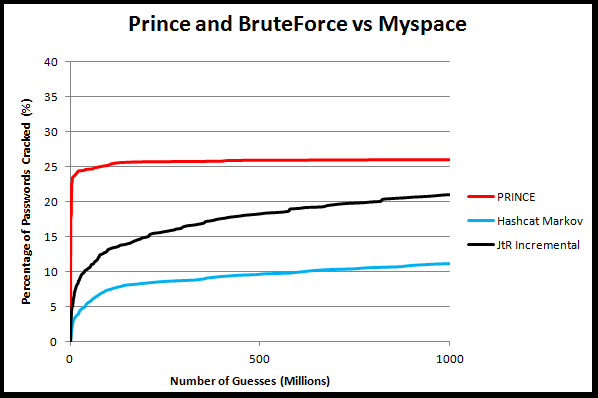
Experiment 3) PRINCE and JtR Wordlist + Incremental mode targeting the MySpace list
Experiment Setup:
Based on feedback from Atom I decided to restructure this next test. First of all, Atom recommended using the full Rockyou list as an input dictionary for PRINCE. Since that is a larger input dictionary than just the first 100k most frequent passwords, I re-ran JtR's single mode ruleset against the MySpace list using the full Rockyou dictionary as well. I also used the most recent version of JtR, 1.8-jumbo1 based on the recommendation of SolarDesigner. This cracked a total of 23,865 passwords from the MySpace list, (slightly more than 64%). I then ran PRINCE, (the newer version 0.13) with the full RockYou dictionary, (ordered), and JtR Incremental=UTF8, (equivalent to "ALL" in the older version of JtR), against the remaining uncracked passwords. I also increased the cracking time to 10 billion guesses.
Side note: I ran a third test PRINCE using the RockYou top 100k input dictionary as well since the newer results were very surprising. I'll talk about that in a bit...
Cracking Length: 10 billion guessesExperiment Setup:
Based on feedback from Atom I decided to restructure this next test. First of all, Atom recommended using the full Rockyou list as an input dictionary for PRINCE. Since that is a larger input dictionary than just the first 100k most frequent passwords, I re-ran JtR's single mode ruleset against the MySpace list using the full Rockyou dictionary as well. I also used the most recent version of JtR, 1.8-jumbo1 based on the recommendation of SolarDesigner. This cracked a total of 23,865 passwords from the MySpace list, (slightly more than 64%). I then ran PRINCE, (the newer version 0.13) with the full RockYou dictionary, (ordered), and JtR Incremental=UTF8, (equivalent to "ALL" in the older version of JtR), against the remaining uncracked passwords. I also increased the cracking time to 10 billion guesses.
Side note: I ran a third test PRINCE using the RockYou top 100k input dictionary as well since the newer results were very surprising. I'll talk about that in a bit...
Commands used:
laki$ ../../../John/john-1.8.0-jumbo-1/run/john -wordlist= ../../../dictionaries/Rockyou_full_ordered.txt -rules=single -stdout | python checkpass2.py -t ../../../Passwords/myspace.txt -u uncracked_myspace.txt
laki$ ../../../Tools/princeprocessor-0.13/pp64.app < ../../../dictionaries/Rockyou_full_ordered.txt | python checkpass2.py -t ../../../Passwords/uncracked_myspace.txt -m 10000000000 -c 23865
laki$ ../../../Tools/princeprocessor-0.13/pp64.app < ../../../dictionaries/Rockyou_top_100k.txt | python checkpass2.py -t ../../../Passwords/uncracked_myspace.txt -m 10000000000 -c 23865
laki$ ../../../John/john-1.8.0-jumbo-1/run/john -incremental=UTF8 -stdout | python checkpass2.py -t ../../../Passwords/uncracked_myspace.txt -m 10000000000 -c 23865
Experiment Results:
I'll guiltily admit before running this test I hadn't been that impressed with PRICE. That's because I had been running it with the top 100k RockYou dictionary. As you can see, with the smaller dictionary it performed horribly. When I ran the new test with the full RockYou dictionary though, PRINCE did significantly better than an Incremental brute force attack. Yes, cracking 1.5% more of the total set might not seem like much, but it will take Incremental mode a *long* time to catch up to that. Long story short though, PRINCE's effectiveness is extremly dependend on the input dictionary you use for it.
Like most surprising test results, this opens up more questions then it solves. For example, what exactly is going on with PRINCE to make it so much more effective with the new dictionary. My current hypothesis is that it is emulating a longer dictionary attack, but I need to run some more tests to figure out if that's the case or not. Regardless, these results show that PRINCE appears to be a very useful tool to have in your toolbox if you use the right input dictionary for it.
Current Open Questions:
- What is the optimal input dictionary to use for PRINCE? Yes the full RockYou input dictionary does well but my gut feeling is we can do better. That leads me to the next open question...
- Can we make PRINCE smarter? Right now it transitions between dictionary attacks and brute force automatically, but beyond sorting the chains by keyspace it doesn't have much advanced logic in it. Perhaps if we can better understand what makes it effective we can make a better algorithm that is even more effective than PRINCE.
Other References:

Comments
> ... as running experiments with various small dictionaries ...
You need to know, there are two different algorithms that can influence each other.
The first one is the algorithm of prince that sorts by keyspace, the second one is the algorihtm that selects the number of password candidates of a specific length X. One can overrule the other one. But, all in all, it is no problem in a real life scenario when a user chooses a realistic output length distribution by using a big enough base wordlist. In that case that problem will not occour.
> Finding #1: Make sure you remove duplicate words from your input dictionary *before* you run PRINCE
Correct
> After PRINCE reads in the input dictionary, it stores each word in a bucket consisting of all the words of the same length. At0m calls these buckets elements
No, that's not the element. That's the table (I did not name this explicitely in the slide but in my talk). An element is a word from your wordlist.
> This isn't to say that it won't generate longer guesses since elements can be longer then length 1. For example with the following input dictionary:
1. The element length doesn't matter at all.
2. There can be an output password candidate of length 20 for example, all it needs it 4 elements of length 5, or 3 of length 1 and 1 of length 17.
> I expected I would see the guess "BigInputaa", but it was nowhere to be found. During the course of my testing, I noticed several other instances of missing chains.
That's a known bug in v0.12 which is fixed in v0.13 available at https://hashcat.net/tools/princeprocessor/
root@et:~/princeprocessor-0.13# cat re
a
bb
BigInput
root@et:~/princeprocessor-0.13# cat re | ./pp64.bin | grep ^BigInputaa$ | wc -l
1
root@et:~/princeprocessor-0.13#
Fixed
> Finding #3: PRINCE is not guaranteed to output all chains in increasing keyspace order, though it appears to at least make an attempt to do so
It's simply again that there are different algorithms can influence each other. In a normal dictionary this will not occour
> --elem-cnt-max=NUM: This limits the number of chains that can be combined to NUM. Aka if you set NUM to 4, then it can combine up to 4 different chains.
No, that means that the total maximum number of elements per chain is 4. For example if the password candidate output length is 8, then there is a total of 128 possible chains. One of them consists of only 1 element, but the others of 2 or more. But only those that consists between the range given with --elem-cnt-min and --elem-cnt-max are allowed and used.
> The rest of the options are pretty self explanatory. One request I would have is for PRINCE to save its position automatically
Makes sense, will add it.
> Performance:
That's a bit an unfair comparison. If you have an embedded attack-mode like incremental, then there's no need for the cracker to parse a text, check the word length, chomp the newline, sort it into some cache, copy it afterwards to the register and so on. Plus its using a pipe from which I don't know how much loss it creates. If you want that comparison to be "correct", you just use john in --stdout mode and pipe it to john in --stdin mode
> The main question of course is how does this tool fit into a cracking session?
I'd say run your rule based attacks first as rule based attacks at the most efficient ones around. But they will exhaust and thats the disadvantage with them. So if you did not succeed to crack the hash in rule based attack mode, start prince afterwards.
> the reality is Atom made some noticeable changes in PRINCE while I was writing this post
Of course prince is brand new and I am fixing "teething problems". ATM the latest release version is v0.13.
> Experiment 1) PRINCE, Hashcat Markov mode, and JtR Incremental mode targeting the MySpace list
> Experiment 2) PRINCE and Dictionary Attacks targeting the MySpace list
> Experiment 3) PRINCE and JtR Wordlist + Incremental mode targeting the MySpace list
Please do not truncate rockyou.txt by any number of top words. Use it as it is.
> Experiment 1) PRINCE, Hashcat Markov mode, and JtR Incremental mode targeting the MySpace list
A comparison using hashcat markov mode is a bit off here. The markov mode in hashcat is in no way meant to be efficient. It's purpuse is mainly to be a bit better than pure brute-force. It has to be compatible with GPGPU and this makes in in some way much harder to write than on CPU. Think of it has to create 16 billions candidates per 10 milliseconds on a single GPU. Yes, billions :)
Statsprocessor is a standalone tool but think of it more like a "test-program". Also v0.10 seems a bit strange as the latest release version is 0.08. I know there was also a beta version but I never released them because of the above reasons.
> Experiment 2) PRINCE and Dictionary Attacks targeting the MySpace list
I'm not really sure why you used hashcat CPU and rules in here. Actually, the rules are not meant to be used alone. It's meant to have princeprocessor feeding words into your cracker and your cracker reading from stdin should also apply those rules. That's a special workaround to have tools like oclHashcat running in full speed while cracking a fast hash.
More important but not covered in your post:
1. Make sure to have your input wordlist sorted by occourance (like rockyou.txt)
2. You did not add the optional personal aspect feature. This makes it in some kind unique compare to any other attack mode.
> Performance:
I agree with you, which is why I wrote that PRINCE was fast ;p
> Please do not truncate rockyou.txt by any number of top words. Use it as it is.
Ok, For the next test I'll run it using the whole rockyou.txt list and the updated version of PRINCE
>Also v0.10 seems a bit strange as the latest release version is 0.08.
I obtained it from: http://hashcat.net/tools/statsprocessor/statsprocessor-0.10.7z
>I'm not really sure why you used hashcat CPU and rules
I was running the tests on my Mac, which meant hascat vs oclhashcat. Also I wanted to run a *hashcat attack since I feel there is a big disconnect between the Hashcat and JtR communities and I want to avoid that as much as possible. While I like JtR from a research standpoint and that's the tool I'm most familiar with, Hashcat is an amazing tool so I want to show examples with that as well.
> You did not add the optional personal aspect feature.
Part of that is I'm not sure how I'd model the experiment against the MySpace list to take advantage of a targeted dictionary against a group or person, (well I could use some myspace related words but that wouldn't have a huge impact).
The change hopefully makes the output more like you would expect it, more like you have described it to be in your section "Algorithm Design". Could you check please?