Analysis of 10k Hotmail Passwords Part 5: Markov Model Showdown
Don't worry; I'm still not done with this data-set. A little over a week ago I received an e-mail from Ilya Sokolov, saying:
If I'm getting the numbers right from your graphs - you've got around 3k hashes bruteforced in about 1G guesses. Assuming you used --incremental mode of John, right? I guess you should try --markov too :)
How right he is. Ilya went on to send some statistics my way, so I truly do appreciate e-mails like this. Before I talk about the results, first let me back up and spend a little time talking about the incremental and markov modes in John the Ripper. Aren't they both Markov based attacks?
--Ed Note: The following description of how the incremental attack works has been updated since I was incorrect about how JtR used trigraphs. A copy of the original incorrect description can be found in the comments.
Well surprisingly yes they are, though they go about it in different ways. The --incremental option actually models the probability of trigraphs appearing. In this case a trigraph represents a three character long string, such as "abc". Another way to say this is that JtR uses trigraphs to represent second order Markov probabilities, aka the probability of 'c' given 'ab'. There's special code handling the first two characters, (since they don't have two characters before them), but after that John the Ripper select each successive character based on the previous characters. Therefore, for the guess 'abcdef', it would create the trigraphs 'abc', 'bcd', 'cde', and 'def', and assign a final probability to the guess based on those four different trigraphs. In addition, the probability of a trigraph is also dependent on where it shows up in the password. In this way, the --incremental attack also takes into account factors such as numbers often show up at the end of a password, and uppercase letters usually are at the front. Pretty nice, right? The only downside is that it doesn't generate these guesses in true probability order. I'm still a little fuzzy on some of it, but the incremental mode does make some shortcuts so it can cover the entire keyspace, while still being able to generate a large number of guesses quickly.
I know; Way to much info - especially since this is just my understanding of how it works. I need to spend more time looking at the code to make sure the above is actually correct. The biggest advantage of using the incremental attack is that it creates highly optimized guesses while still retaining the ability to eventually cover the entire key-space if you give it enough time. Aka it will eventually try guesses like 'bD359sl'. Also it is blazingly fast.
The --markov mode on the other hand takes a different approach. First of all, if you haven't noticed this option in your copy of John the Ripper, that is because it was added as a third party patch, (though it's currently part of the jumbo patch set). Personally I haven't used it that much since it full out segfaults on Intel based macs, which I generally use as my development/testing platform. That being said, after running some comparative tests on my Linux box at the lab, (I use that one for my long term password cracking sessions), I've really become a believer in it. However, using the markov mode is a little bit tricky.
Unlike incremental mode, the markov mode does not use trigraphs. Instead it starts with the highest probability starting letter, (in the default stats file this is a 'c'), and then appends the most probable following character. It repeats this until it hits the probability threshold specified, or it reaches 12 characters long, in which case it outputs a password guess. The attack then goes to the last character of the previous guess and changes it to the second most probable value, and outputs another guess. You can probably see where this is going as it cycles through printing out all the possible guesses that meet the probability threshold specified. There are a lot of advantages to this approach. For example, it can attack passwords up to twelve characters long. The downsides of this approach is that it doesn't create guesses in probability order which the incremental attack does. Therefore, as we will see, if you set a high threshold the markov mode starts to resemble a letter frequency analysis attack. Finally, because of this, the markov mode won't cover the entire key-space, (aka, it won't crack the password '3Nw!lswp'). The last point isn't as important as it may seem though, since in all likelihood due to time constraints, (aka you only have several months to crack a password if that), you simply don't have enough time to cover the entire key-space even using incremental mode. In short, you want to do the best that you can with the limited number of guesses you can make.
So that was a really long introduction before we even talked about any results ;) Let's see how the incremental and markov options fare against some real passwords!
Test 6: Trying the default -incremental and -markov modes against the Hotmail password set
For the first test, I wanted to run both the -incremental and -markov modes against the Hotmail password set using their default settings. The one tricky part was to set the limit for the markov attack. In the readme file for the patch, it actually goes into quite a bit of detail on how to select a proper limit. Really all I did was run the included program 'genmkvpwd', and select a limit that would cause the attack to generate slightly more than one billion guesses. This turned out to be the value '214' for the limit.
Results: So here are the results. As always, you can click on the graph to get a slightly larger version. The Y-axis is the number of passwords cracked. Sorry, I didn't realize I forgot to add that until I was proof-reading this and I didn't feel like re-uploading the graphs.
-ed note: I know; It certainly doesn't look like I proof-read these posts ;)
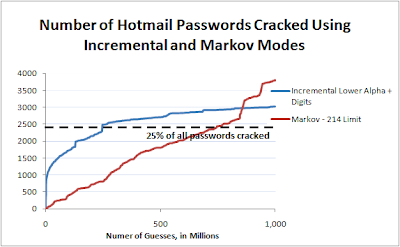
Analysis: As you can see, the Markov mode started out slow, but finished strong, cracking 786 more passwords than the Incremental attack. As far as I can tell, the reason why it did so well near the end was that the markov mode started trying password guesses that began with numbers, which was very common in the hotmail dataset. Also, since the probability of a guess starting with a number was so low according to the default rule-set, it only tried very probable guesses following a number.
Another thing I'd like to point out: Due to the way it creates guesses, for the most part the Markov mode cracks passwords at a fairly fixed rate; while the Incremental mode is much more front-loaded. I'd like to caution you against extending the Markov mode's line though, as it has finished just about every password guess within the limit that I set. That actually leads us to the next test...
Test 7: Setting Different Limits for a Markov Based Attack
So the next question of course is, "How does the limit affect Markov based attacks?" That's a pretty easy one to solve. All I needed to do was run it with several different limits and graph the results. I also included the Incremental results for a comparison.
Results:

Analysis: See what I mean about not being able to continue a predictive line on the number of passwords that using JtR in Markov mode will crack? When using a limit of 200, it created slightly more than 250 million guesses and then finished. If we run the same attack using a limit of 214, it will create almost four times as many guesses, but it only cracks 148 more passwords. If we increase the limit to 250, it will generate roughly 46 billion guesses; But if you refer back to some of the previous tests, even a pure brute force attack performs significantly better in the first billion guesses. Don't worry though, as the Markov attack will catch up with brute force, (and then exceed it by a large margin), if you let it run long enough.
What this shows is that you really do need to spend the time to tailor your attacks using Markov mode to the resources you expect to spend cracking the password list you are attacking. One good option is you can split your attack up into multiple parts, where you try all the guesses using a very low limit, and then increase the limit and run the attack again. There is an option in the latest build of the patch to exclude guesses made previously. This can save you time since you don't have to re-hash guesses you made already. There is a slight performance hit by using this approach though as it will make a guess, realize that it made the guess before and reject it, before moving on to the next guess. Still, this can be very useful, especially when attacking salted hashes, as it makes a huge performance improvement to crack as many hashes as possible as soon as possible, (since each hash you are cracking greatly adds to the cracking time).
Test 8: Comparing Incremental and Markov Modes When Trained on the Same Password Set
Now, all of the previous tests are fairly nice, but there is the worry that we are comparing apples and oranges. I mean, both the default Markov and Incremental modes were trained on different password sets, and that can have a huge impact on their cracking ability. For example, the Markov mode was trained primarily on French passwords, and the Incremental attack was mostly trained on English passwords. That's one nice thing about being in the password cracking research business though; I certainly have a lot of passwords to use for my own training set ;)
For this test, I trained both the Incremental and Markov modes on the same set of disclosed passwords from the phpbb.com list that I had previously cracked. In technical terms, I created a new .chr and new stats file for both attacks. As I previously mentioned in part 4 of the writeup, the phpbb.com list isn't ideal for this attack since it is primarily composed of English passwords, while this list is mostly Spanish/Portuguese, but that doesn't matter for this test. What does matter is both attacks are being trained on the same list, and they have to deal with the same limitations. In addition, I ran the Markov attack twice. The first time I allowed it to attack passwords up to 12 characters long. The second time I limited it to only attack passwords up to 8 characters long, (and I assigned it a higher limit so it would generate roughly the same number of guesses). This way we can better compare it against JtR's incremental mode which only tries guesses up to 8 characters long. So, let's see how this turned out:
Results:

Analysis: Yup, the Markov mode still cracks more passwords than JtR's Incremental mode. Still, there were a couple of things that surprised me about these results. First of all, the phpbb.com list made a much better training list than using the default .chr and stat files. The Markov attack cracked 540 more passwords using the same number of guesses when it was trained on the phpbb list. The Incremental attack also got off to a much faster start, though in the end it cracked 17 less passwords than the Incremental attack using the default alphanum character set. This isn't exactly a fair comparison though since I didn't bother to filter the training set to only include lowercase letters and numbers.; Aka it actually is using pretty much the entire keyboard. In that case, it performs much better than using JtR's Incremental mode using the 'All' .chr file, and it cracked 333 more passwords overall.
The second thing that surprised me was that limiting the maximum password guess size didn't really have much of an effect on the number of passwords cracked using the Markov mode. This shouldn't have surprised me that much, since it didn't make that many guesses longer than eight characters long, (the probability of those guesses would be very low), but still it helps to see that on a graph.
Future Work: Whew, and here I thought I'd be done with this data-set by now. I still have a few miscellaneous tests I want to run using brute force style methods believe it or not. And then I need to get around to posting my results with dictionary based attacks. Oh ,then there are the topics that I've been meaning to post on for a while. They range from going over other datasets, (such as the ZF0 one), to the vulnerability of World of Warcraft accounts to password disclosure attacks, (and what Blizzard is doing about it). It should be fun ;)
I know; Way to much info - especially since this is just my understanding of how it works. I need to spend more time looking at the code to make sure the above is actually correct. The biggest advantage of using the incremental attack is that it creates highly optimized guesses while still retaining the ability to eventually cover the entire key-space if you give it enough time. Aka it will eventually try guesses like 'bD359sl'. Also it is blazingly fast.
The --markov mode on the other hand takes a different approach. First of all, if you haven't noticed this option in your copy of John the Ripper, that is because it was added as a third party patch, (though it's currently part of the jumbo patch set). Personally I haven't used it that much since it full out segfaults on Intel based macs, which I generally use as my development/testing platform. That being said, after running some comparative tests on my Linux box at the lab, (I use that one for my long term password cracking sessions), I've really become a believer in it. However, using the markov mode is a little bit tricky.
Unlike incremental mode, the markov mode does not use trigraphs. Instead it starts with the highest probability starting letter, (in the default stats file this is a 'c'), and then appends the most probable following character. It repeats this until it hits the probability threshold specified, or it reaches 12 characters long, in which case it outputs a password guess. The attack then goes to the last character of the previous guess and changes it to the second most probable value, and outputs another guess. You can probably see where this is going as it cycles through printing out all the possible guesses that meet the probability threshold specified. There are a lot of advantages to this approach. For example, it can attack passwords up to twelve characters long. The downsides of this approach is that it doesn't create guesses in probability order which the incremental attack does. Therefore, as we will see, if you set a high threshold the markov mode starts to resemble a letter frequency analysis attack. Finally, because of this, the markov mode won't cover the entire key-space, (aka, it won't crack the password '3Nw!lswp'). The last point isn't as important as it may seem though, since in all likelihood due to time constraints, (aka you only have several months to crack a password if that), you simply don't have enough time to cover the entire key-space even using incremental mode. In short, you want to do the best that you can with the limited number of guesses you can make.
So that was a really long introduction before we even talked about any results ;) Let's see how the incremental and markov options fare against some real passwords!
Test 6: Trying the default -incremental and -markov modes against the Hotmail password set
For the first test, I wanted to run both the -incremental and -markov modes against the Hotmail password set using their default settings. The one tricky part was to set the limit for the markov attack. In the readme file for the patch, it actually goes into quite a bit of detail on how to select a proper limit. Really all I did was run the included program 'genmkvpwd', and select a limit that would cause the attack to generate slightly more than one billion guesses. This turned out to be the value '214' for the limit.
Results: So here are the results. As always, you can click on the graph to get a slightly larger version. The Y-axis is the number of passwords cracked. Sorry, I didn't realize I forgot to add that until I was proof-reading this and I didn't feel like re-uploading the graphs.
-ed note: I know; It certainly doesn't look like I proof-read these posts ;)

Analysis: As you can see, the Markov mode started out slow, but finished strong, cracking 786 more passwords than the Incremental attack. As far as I can tell, the reason why it did so well near the end was that the markov mode started trying password guesses that began with numbers, which was very common in the hotmail dataset. Also, since the probability of a guess starting with a number was so low according to the default rule-set, it only tried very probable guesses following a number.
Another thing I'd like to point out: Due to the way it creates guesses, for the most part the Markov mode cracks passwords at a fairly fixed rate; while the Incremental mode is much more front-loaded. I'd like to caution you against extending the Markov mode's line though, as it has finished just about every password guess within the limit that I set. That actually leads us to the next test...
Test 7: Setting Different Limits for a Markov Based Attack
So the next question of course is, "How does the limit affect Markov based attacks?" That's a pretty easy one to solve. All I needed to do was run it with several different limits and graph the results. I also included the Incremental results for a comparison.
Results:

Analysis: See what I mean about not being able to continue a predictive line on the number of passwords that using JtR in Markov mode will crack? When using a limit of 200, it created slightly more than 250 million guesses and then finished. If we run the same attack using a limit of 214, it will create almost four times as many guesses, but it only cracks 148 more passwords. If we increase the limit to 250, it will generate roughly 46 billion guesses; But if you refer back to some of the previous tests, even a pure brute force attack performs significantly better in the first billion guesses. Don't worry though, as the Markov attack will catch up with brute force, (and then exceed it by a large margin), if you let it run long enough.
What this shows is that you really do need to spend the time to tailor your attacks using Markov mode to the resources you expect to spend cracking the password list you are attacking. One good option is you can split your attack up into multiple parts, where you try all the guesses using a very low limit, and then increase the limit and run the attack again. There is an option in the latest build of the patch to exclude guesses made previously. This can save you time since you don't have to re-hash guesses you made already. There is a slight performance hit by using this approach though as it will make a guess, realize that it made the guess before and reject it, before moving on to the next guess. Still, this can be very useful, especially when attacking salted hashes, as it makes a huge performance improvement to crack as many hashes as possible as soon as possible, (since each hash you are cracking greatly adds to the cracking time).
Test 8: Comparing Incremental and Markov Modes When Trained on the Same Password Set
Now, all of the previous tests are fairly nice, but there is the worry that we are comparing apples and oranges. I mean, both the default Markov and Incremental modes were trained on different password sets, and that can have a huge impact on their cracking ability. For example, the Markov mode was trained primarily on French passwords, and the Incremental attack was mostly trained on English passwords. That's one nice thing about being in the password cracking research business though; I certainly have a lot of passwords to use for my own training set ;)
For this test, I trained both the Incremental and Markov modes on the same set of disclosed passwords from the phpbb.com list that I had previously cracked. In technical terms, I created a new .chr and new stats file for both attacks. As I previously mentioned in part 4 of the writeup, the phpbb.com list isn't ideal for this attack since it is primarily composed of English passwords, while this list is mostly Spanish/Portuguese, but that doesn't matter for this test. What does matter is both attacks are being trained on the same list, and they have to deal with the same limitations. In addition, I ran the Markov attack twice. The first time I allowed it to attack passwords up to 12 characters long. The second time I limited it to only attack passwords up to 8 characters long, (and I assigned it a higher limit so it would generate roughly the same number of guesses). This way we can better compare it against JtR's incremental mode which only tries guesses up to 8 characters long. So, let's see how this turned out:
Results:

Analysis: Yup, the Markov mode still cracks more passwords than JtR's Incremental mode. Still, there were a couple of things that surprised me about these results. First of all, the phpbb.com list made a much better training list than using the default .chr and stat files. The Markov attack cracked 540 more passwords using the same number of guesses when it was trained on the phpbb list. The Incremental attack also got off to a much faster start, though in the end it cracked 17 less passwords than the Incremental attack using the default alphanum character set. This isn't exactly a fair comparison though since I didn't bother to filter the training set to only include lowercase letters and numbers.; Aka it actually is using pretty much the entire keyboard. In that case, it performs much better than using JtR's Incremental mode using the 'All' .chr file, and it cracked 333 more passwords overall.
The second thing that surprised me was that limiting the maximum password guess size didn't really have much of an effect on the number of passwords cracked using the Markov mode. This shouldn't have surprised me that much, since it didn't make that many guesses longer than eight characters long, (the probability of those guesses would be very low), but still it helps to see that on a graph.
Future Work: Whew, and here I thought I'd be done with this data-set by now. I still have a few miscellaneous tests I want to run using brute force style methods believe it or not. And then I need to get around to posting my results with dictionary based attacks. Oh ,then there are the topics that I've been meaning to post on for a while. They range from going over other datasets, (such as the ZF0 one), to the vulnerability of World of Warcraft accounts to password disclosure attacks, (and what Blizzard is doing about it). It should be fun ;)


{kind=link}
Comments
The --incremental option actually models the probability of trigraphs appearing. In this case a trigraph represents a 1-3 character long string, such as "abc". It then uses these trigraphs to model the conditional probability of three letter groupings, (aka their Markov probability). The problem is that JtR's incremental attack doesn't model the conditional probability of trigraphs appearing together. That certainly is not a deal breaker, (as seen from the previous results). The incremental attack takes into account the password length and where a trigraph appears in a password guess. Aka, the probability that a particular trigraph will be assigned depends on if it appears at the beginning, middle or end of a password guess. Unfortunatly it doesn't take into account the previous trigraphs that appeared before it, (except when calculating the overall probability). For example, if the first trigraph is "auq", the next trigraph's probability isn't increased if it starts with a 'u', (even though 'u' almost always follows 'q'). Therefore, the incremental attack doesn't measure the conditional probability between the third and fourth letter, and the sixth and seventh letter of a password guess.